目录
不是标题党。完整还原了 chat.z.ai 的签名算法,纯 Python 实现,不依赖任何浏览器。
01
先说结果。
几小时,一个 AI Agent(Codex),一个反检测浏览器工具(camoufox-reverse MCP),加上一套逆向工作流 Skill。
最终产出了什么?
智谱清言(chat.z.ai)的完整签名算法还原——包括那个让人头疼的 ssxmod_itna Cookie 生成逻辑,以及 SSE 流式对话接口的协议客户端。
纯 Python,不挂浏览器,独立运行。
听起来是不是有点离谱?但这就是 AI 辅助逆向的真实面貌——它不会替你思考,但能在你指对方向后,以你一个人根本做不到的速度跑完整个流程。
这篇文章不卖课,不制造焦虑。我把它完整写下来,因为这个过程里有太多值得分享的东西——不只是技术层面的,更多的是怎么跟 AI 协作的方法论。
不管你是做逆向的同行,还是想看看 AI 到底能帮到什么程度,这篇文章都值得一看。
02
这件事为什么值得做
如果你做过 Web 逆向,应该知道这个痛点:
大多数现代网站都有一层"保护壳"——请求不是直接发出去的,而是经过一套复杂的签名机制。Cookie 要动态生成,参数要加密,请求头里还塞着各种签名和时间戳。
传统的手工抓包分析方式,效率低、难以复现,而且很容易漏掉关键的环境校验点。
以前做逆向,你需要:
- 打开浏览器开发者工具,一条条看请求
- 在混淆后的 JS 代码里大海捞针找加密函数
- 手动 Hook、手动打断点、手动记录变量
- 猜算法、试算法、猜错了再重来
这次我们换了个方式:
用 AI Agent 作为"大脑",用 MCP 工具作为"手脚"。AI 负责分析和推理,MCP 工具负责自动化浏览器操作、网络抓包、源码搜索、Hook 注入。
相当于给 AI 装上了一双能看到浏览器内部的眼睛和一只能操作浏览器的手。
效果如何?往下看。
03
这套工具链是怎么工作的
简单说,就是三个组件配合:
Codex(AI Agent)——负责分析、推理、写代码。相当于团队里的"大脑"。
camoufox-reverse MCP——一个反检测浏览器自动化工具,提供了 57 个逆向分析工具。从启动浏览器、抓包、搜索 JS 源码、Hook 函数到追踪调用栈,全部覆盖。相当于"手脚"。
hello_js_reverse_skill——一套定义好的工作流程和规范。告诉 AI 什么时候用哪个工具、按什么顺序、遵循什么规则。相当于"操作手册"。
整个协作流程是这样的:
人类发出指令 │ ▼ Codex(AI)分析 + 推理 │ ▼ 通过 MCP 控制 Camoufox 浏览器 │ (抓包、Hook、源码搜索、调用链追踪) ▼ AI 分析结果 + 生成代码 │ ▼ Python 纯算法还原,独立运行
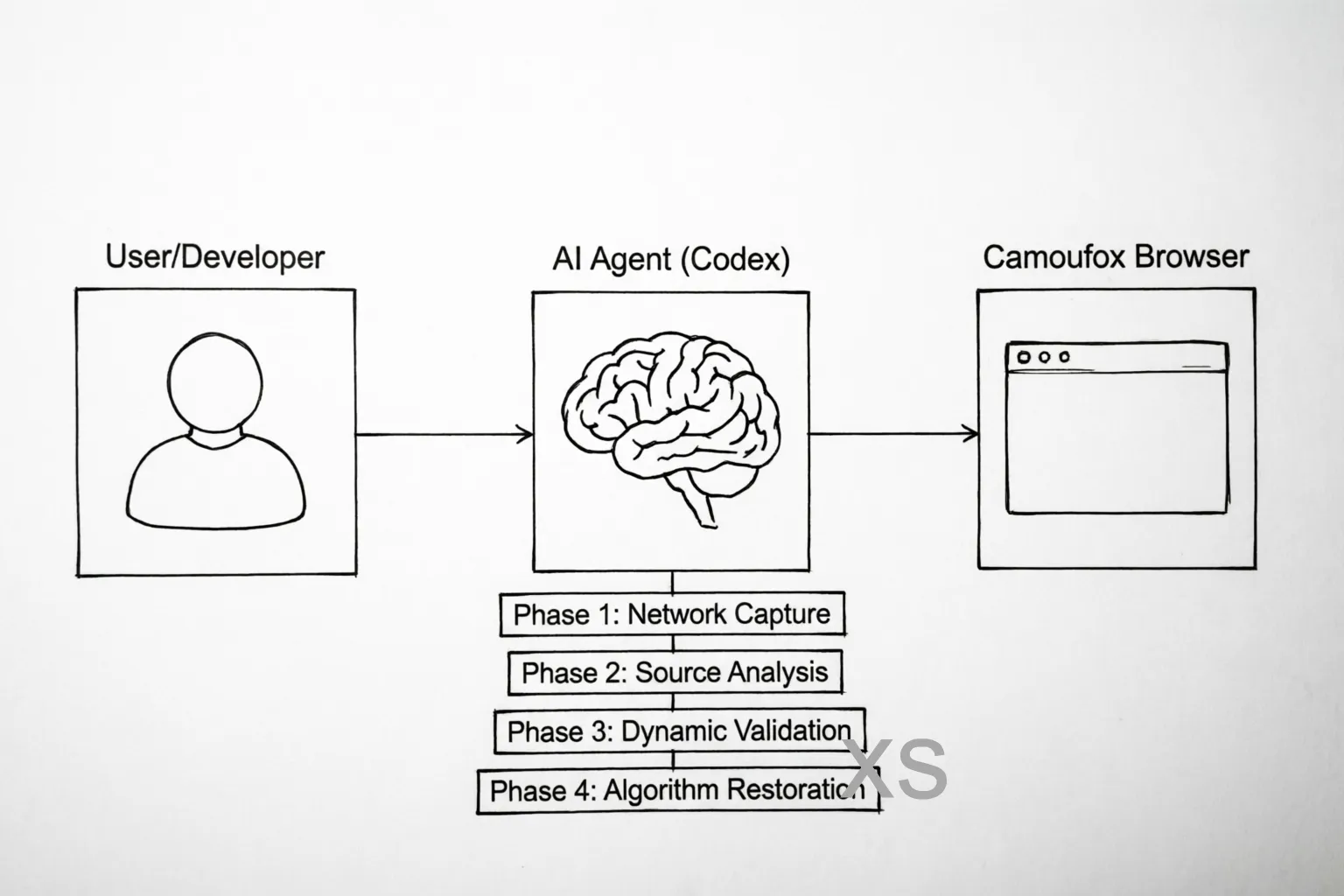
图:MCP 工具协作架构,展示 Codex Agent 通过 MCP 协议控制 Camoufox 浏览器完成逆向分析全链路
这个架构最爽的地方在于:一旦启动,AI 可以连续工作很久,不需要你盯着每一步。 你只需要在关键节点给出反馈和纠正。
04
四阶段,AI 是怎么一步步破解的
整个逆向过程分了四个阶段。
第一阶段:先把目标"盯"清楚
第一步很简单——让 AI 启动一个反检测浏览器,访问 chat.z.ai,登录,然后开始对话。
但关键不在于"访问",而在于记录。
AI 在后台做了几件事:
- 开启网络抓包,捕获所有 HTTP/HTTPS 请求
- 列出捕获的请求,找到关键的对话接口(
/api/v2/chat/completions) - 获取完整的请求头、请求体、响应格式
- 最重要的一步:用
get_request_initiator从请求直接定位到发起它的 JS 调用栈
这一步是"黄金路径"——你不需要在几万行混淆代码里大海捞针,从网络请求就能直接找到签名函数在哪里。
第二阶段:锁定加密参数
有了调用栈,AI 开始追踪那些可疑的函数:
- 用
hook_function对加密函数进行 Hook - 用
trace_function追踪函数调用链 - 用
get_trace_data获取参数生成的完整输入输出 - 在所有已加载的 JS 中搜索关键词(
ssxmod、encrypt、sign)
关键发现:ssxmod_itna Cookie 的生成逻辑——它就是那个最难啃的骨头。
第三阶段:动态验证
找到加密函数还不够,得确认我们理解得对不对。
AI 的做法是:
- 预设 Hook 拦截 fetch 请求和加密调用
- 刷新页面重新触发
- 读取 Hook 输出,对比多次请求的结果
- 确认哪些参数每次都在变,哪些是固定的
第四阶段:纯算法还原
最后一步,也是最关键的一步——脱离浏览器,用 Python 从头实现。
要求很明确:
- 不依赖浏览器环境
- 不用 Selenium、Playwright 等自动化工具
- 纯算法,独立运行
最终实现了加密参数生成、Cookie 生成、用 httpx 发送请求(支持 TLS 指纹模拟),以及 SSE 流式响应的接收和解析。
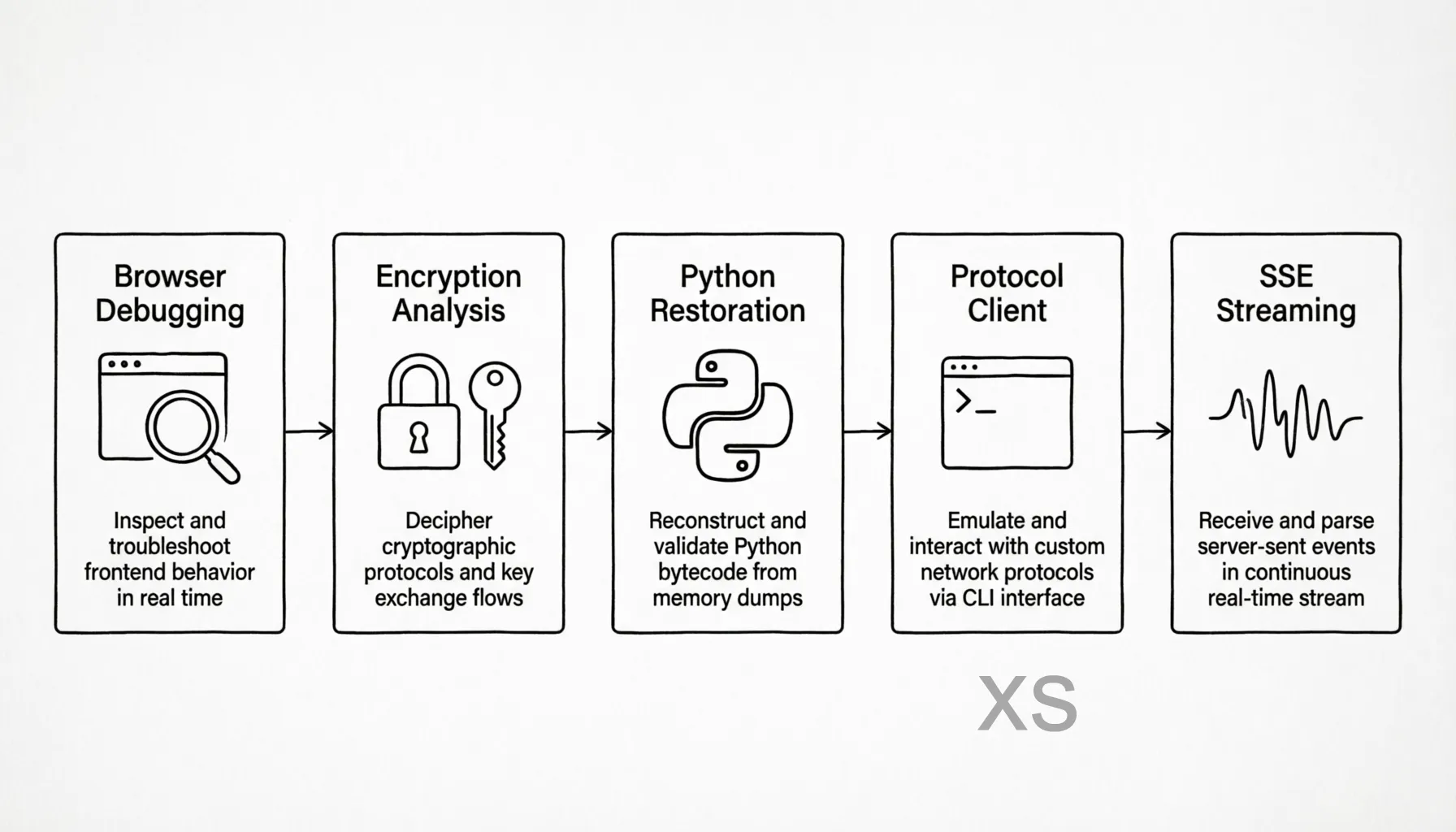
图:从浏览器调试到协议客户端的完整逆向流水线
05
但 AI 不是万能的——4 个真实纠正案例
到这里你可能会觉得,"哇,AI 这么厉害,扔个问题就自动搞定了?"
当然不是。
这正是我要重点分享的部分——AI 很强,但它会犯错、会偷懒、会过度自信。而发现错误并纠正它,正是人类开发者的核心价值所在。
下面这四个案例,是这次项目中最有价值的部分。
案例一:AI 说"这算法和雪球一样",我说"你确定?"
AI 的判断:
在分析 ssxmod_itna Cookie 时,AI 基于参数名称特征判断:"这个和雪球财经(xueqiu.com)的签名算法一样,直接复用雪球的方案。"
我的纠正:
我只问了一句:
"ssxmod_itna 和雪球的一样吗?"
结果:
AI 把不同站点的算法混为一谈了。虽然有一些相似之处,但核心机制不同。如果不纠正,AI 会在错误的算法假设上浪费大量时间。
教训:AI 会"认脸"——看到相似的参数名就以为是一回事。不要被它的自信带偏,用真实数据验证。简短的一个确认问题,就能避免大量返工。
案例二:AI 说"联网搜索和深度思考都支持了",我说"结果不对"
AI 的表现:
模型声称 CLI 客户端已经支持"联网搜索"和"深度思考"功能。但实际用起来有问题——同一问题在浏览器和 CLI 中结果不一致。
我用的测试问题是:"2026 年最受欢迎的职业发展规划问答社区是哪个"
浏览器里会显示参考文献标识,CLI 里没有。等待时间也对不上——浏览器要很久,CLI 一下子就出来了。
我的纠正:
"目前的深度思考和联网搜索似乎不是正确的。联网搜索如果有参考文献在原本中是有标识的,我用同样的问题询问,CLI 和浏览器的不一样。"
结果:
AI 没有正确传递深度思考和联网搜索的开关参数。对比测试直接暴露了问题。
教训:当 AI 说"功能已实现"时,用相同输入对比浏览器和代码端的结果,是最有效的验证方法。不要只看"能不能跑通",要看"跑出来的结果对不对"。
案例三:AI 做了个功能齐全但没人想用的 CLI
AI 的过度设计:
模型构建的 CLI 客户端包含了大量参数和复杂的解析逻辑,远超实际需求。
我的纠正:
我直接列出了需要的最小接口:
"CLI 太复杂,我不要 CLI 模式。我会自己调用函数,不要这么多参数可传递。我只需要:提示词、模型选择、代理配置、开启联网搜索(普通和高级)、开启深度思考。"
5 个核心配置项,其他都不要。
结果:
代码清爽了不止一个量级。总超时无限,只在连续 300 秒没有新数据时才退出。每个数据块超时 300 秒。默认启用 ssxmod 模式,不需要传递参数。
教训:AI 会本能地"过度工程化"——它倾向于把所有能想到的功能都做上去。你需要明确告诉它最小可用接口是什么。少即是多。
案例四:从乱七八糟到三个文件搞定一切
AI 的混乱:
随着代码迭代,项目文件变得杂乱。Cookie 生成逻辑散落在多个文件中,浏览器指纹配置到处都是。
我的纠正:
"整理好文件。这个 Cookie 我只需要两个文件,一个是 profile,一个是 generate。对话里所需要的所有和浏览器指纹相关的配置都从 profile 里获取。"
最终结构:
project/ ├── browser/ │ ├── profile.py # 浏览器指纹配置生成 │ └── cookie.py # Cookie 生成逻辑 ├── z_ai.py # 协议客户端主逻辑 └── README.md
三个文件,职责清晰:
profile.py——生成浏览器信息(支持多平台多浏览器:Windows/macOS、Firefox/Chrome/Edge)cookie.py——生成 Cookiez_ai.py——协议客户端主逻辑
教训:AI 不会自动维护代码结构。你需要在合适的时候介入,要求它整理文件。好的结构让后续维护成本直线下降。
06
Skill 到底是什么?为什么它这么重要
上面说的四个纠正案例中,其实有一条暗线——好的 Skill(工作流定义)能大幅减少你需要纠正的次数。
这次的 hello_js_reverse_skill 定义了一套完整的工作流程,相当于给 AI 装上了一个"领域专家大脑"。
它不只是告诉 AI "你能用什么工具",更重要的是定义了:
工作阶段——Phase 0 到 Phase 5,每个阶段该做什么、不该做什么,清清楚楚。
行为规则——证据驱动、禁止猜测、一次执行到底。
工具使用规范——什么时候用哪个 MCP 工具、怎么组合使用。
黄金路径优先——优先用 get_request_initiator 从请求直接定位签名函数,而不是在 JS 代码海里盲目搜索。
| Skill 规则 | 实际效果 |
|---|---|
| 浏览器连接策略 | AI 自动启动独立 Camoufox 实例,不接管用户浏览器 |
| 黄金路径优先 | 从请求直接定位签名函数,不走弯路 |
| 证据驱动 | 所有结论必须有 Hook 数据或源码证据 |
| 一次执行到底 | 不在中间步骤暂停,连续完成全部分析 |
| 配置外置 | 长内容写配置文件,不硬编码在代码里 |
如果没有这套 Skill,AI 的工作方式会像这样:东一榔头西一棒槌,一会儿去搜索代码,一会儿去 Hook 函数,一会儿又试图重新抓包。有了 Skill,它的工作方式变得有序——按阶段推进,每个阶段都有明确的目标和输出。
简单说:Skill 就是把你的经验教训编码成 AI 能理解的指令集。 你踩过的坑,写进 Skill 里,AI 就不会再踩。
07
这趟旅程的五条核心经验
如果你也想用 AI 来做类似的工作,这五条建议可以直接拿去用。
1. 对比测试,胜过一切信任
当怀疑 AI 的实现有误时,用相同的输入对比浏览器端和代码端的结果差异。
这是发现功能实现偏差最有效的方法。不要问 AI "你确定对吗?"——它总会说"对"。要看结果。
2. 纠正要短、要准、要狠
纠正信息越简短越好。
- 无效:写一段 200 字的分析,解释为什么算法不同
AI 对简短关键词的响应效果远好于长篇大论。精准一个词,胜过千言万语。
3. 明确最小可用接口
当 AI 过度设计时,直接列出你需要的最小参数集,删除所有不必要的复杂逻辑。
AI 的本能是"多做点",你的工作是告诉它"这些就够了"。
4. 先要方案,再让动手
对于复杂的修改,要求 AI 先输出方案,确认方案正确后再执行。
"你要怎么做?先告诉我方案,不要立刻执行。"
这比"让它先做,做错了再纠正"效率高十倍。
5. 每次只纠正一个方向
在长会话中,每次只纠正一个点,确认 AI 理解后再进入下一个纠正点。
不要一次性推翻所有结论。这会导致 AI 重新分析时连之前正确的部分也搞错了。
08
最后想说
这个项目让我最深刻的体会是:
AI 不会替你思考。但它能在你指对方向后,以一个人根本做不到的速度跑完整个流程。
关键不是"AI 有多强",而是你怎么引导它、怎么纠正它、怎么把经验沉淀成可复用的工作流。
这次我们用 AI 完成了智谱清言 API 的签名算法还原。下次可能是别的什么。但方法论是通用的——不管是逆向、数据分析、还是任何需要大量重复验证的工作。
如果你有类似的经验或者想法,欢迎在评论区聊聊。
项目信息
| 指标 | 结果 |
|---|---|
| 目标接口 | chat.z.ai /api/v2/chat/completions |
| 加密参数还原 | ssxmod_itna Cookie 生成算法 |
| 协议客户端 | Python 纯算法实现,不依赖浏览器 |
| SSE 支持 | 流式响应接收与解析 |
| 代码结构 | browser/profile.py + cookie.py + z_ai.py |
如果觉得这篇文章对你有帮助,欢迎分享给更多人。 有任何问题或想法,在评论区见 👇


本文作者:回锅炒辣椒
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!